
Завод для ввода данных — реальная цифровизация архивов, ускорение процесса современного офисного управления
2023-09-14Высокие темпы развития электронных архивов

С непрерывным развитием науки и техники, архивы в области новых технологий продолжают появляться, а также дальнейшая популярность автоматизации офиса, традиционное управление архивами не в состоянии адаптироваться к потребностям развития новых технологий. Как сохранить хорошие электронные архивы, становится все более заметной проблемой, стоящей перед архивистами.
Центральный комитет партии, Государственный совет и некоторые провинции и муниципалитеты по всей стране, партийные и правительственные органы приняли безбумажный офис, правительство Китая также создало ведущую группу по архивированию электронных документов и исследованию управления электронными архивами, и постепенно разрабатывает соответствующие методы управления для широкой популярности электронных архивов, чтобы заложить основу. Кроме того, финансы, учреждения и другие отрасли активно совершенствуются и создают условия для перехода от бумажных носителей документов к электронному управлению файлами, которое развивается высокими темпами.
Традиционный ручной ввод не смог удовлетворить требования, как преобразовать бумажные документы в электронные файлы, научное и эффективное управление электронными архивами, распознавание текста OCR является одним из незаменимых звеньев.
Распознавание текста OCR - Wintone

Wintone в области OCR более 30 лет глубокой вспашки, запустила ряд отличных, практических продуктов OCR распознавания текста: TH-OCR интегрированная система распознавания текста, система распознавания текста меньшинства, IT-сканирование файла легко сканировать через, TH-OCR завод ввода данных, интегрированная система распознавания текста - локализованные, общие продукты распознавания текста и т.д., был в архивах, газетах, библиотеках, правительства, учреждений и других учреждений успешно применяется, из которых продукты завода ввода данных стали предпочтительным выбором крупных учреждений. Она успешно применяется в архивах, газетах, библиотеках, правительствах, учреждениях и других организациях, среди которых продукты фабрики ввода данных стали первым выбором крупных организаций.
Фабрика по вводу данных - Подробнее

Wint Data Entry Factory, т.е. интеллектуальный инструмент распознавания и обработки изображений, может преобразовывать различные изображения документов в извлекаемые двухслойные файлы PDF/TXT/RTF, распознавать упрощенный китайский, традиционный китайский, рукописный, чисто английский, японский, корейский и другие языки, осуществлять электронную обработку огромных объемов данных, а также устанавливать всесторонние и трехмерные связи с крупными газетными компаниями и предприятиями по обработке данных.
I. Функции обработки изображений
Поддерживает поворот изображения, удаление областей, обрезку изображения, коррекцию наклона и другие виды обработки изображений, автоматически корректирует неровные изображения, например наклонные, улучшает качество изображения и повышает скорость распознавания.
II. Анализ макета

Data Entry Factory выполняет автоматический анализ макета журналов, книг, газет и других публикаций. Макет классифицируется на четыре типа: горизонтальный текст, вертикальный текст, изображения и таблицы. Правильный анализ макета позволяет улучшить распознавание. Пользователи также могут выполнять анализ макета вручную в соответствии со своими потребностями.
Самообучение
Для древних книг, научных исследований и других специальных областей документов, часто появляющихся в специальном тексте, пользователь может использовать функцию самообучения для изучения образа этих слов в системе, так что настроенное ядро может поддерживать распознавание этих слов.
В-четвертых, горизонтальная корректура
Распознавание оригинального изображения блока отслеживания отображения на результаты распознавания, так что результаты распознавания и оригинальное изображение один-к-одному отображение соответствия, легко изменить ошибку, интуитивно понятный, удобный и быстрый.
V. Вертикальная корректура
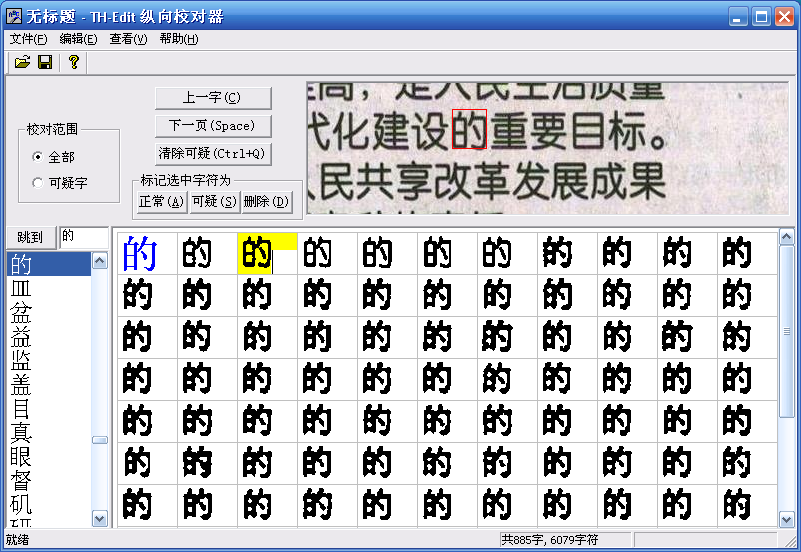
Перестройте порядок текста, выведите на экран изображения, соответствующие одному и тому же тексту с одинаковым результатом распознавания, и вы не сможете пропустить неправильные слова, а вычитка будет эффективной и неутомительной.
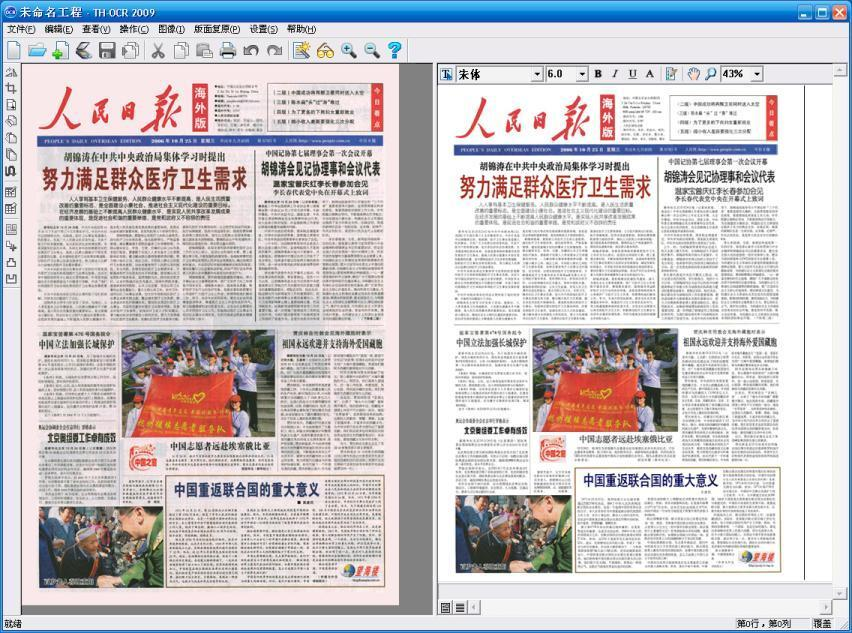
Шесть, мощная технология восстановления макета
Восстановление шрифтов, размеров шрифта, положения макета, цвета шрифта и другой информации для создания высококачественных голографических PDF-документов, распознавания газет, журналов, книг и других форм документов в оригинальном стиле перед читателем.

Семь, различные форматы импорта и экспорта
Поддержка TIF, BMP, JPG, PDF и других форматов изображений импорта файлов распознавания, результаты распознавания после модификации и редактирования, в соответствии с требованиями пользователя необходимо сохранить документ в качестве восстанавливаемого RTF, двухслойные PDF, TXT формат документов, точное восстановление макета.
Другие продукты для распознавания текста

