- SDK для распознавания текста TH-OCR
- OCR-распознавание текста - Китай
- OCR для национальных меньшинств
Описание функций
-
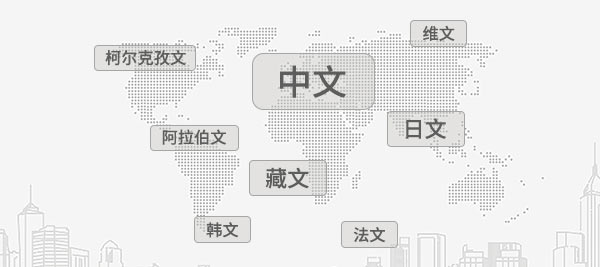
Поддержка множества языков для OCR-распознавания
Поддержка распознавания упрощенного и традиционного китайского, тибетского, уйгурского, казахского, арабского и других языков.

-
Широкий набор символов для OCR-распознавания
Поддержка распознавания редких символов, возможность создания наборов символов более 16 000.

-
Настраиваемые разработки для набора символов
Возможность разработки и создания новых наборов символов по запросу пользователя.

-
Многократный анализ текста различных макетов
TH-OCR поддерживает распознавание текста на языках меньшинств, включая горизонтальный и вертикальный текст, таблицы, изображения и другие типы макетов.

-
Мощная обработка изображений
TH-OCR для языков меньшинств поддерживает функции автоматической коррекции наклона, автоматической ориентации, удаления подчеркиваний, удаления загрязнений и автоматической обрезки.

-
Интеллектуальная фильтрация помех
TH-OCR для языков меньшинств автоматически фильтрует помехи от наклона, деформации, изменений освещенности, пересечений линий, сетки, печатей, размытия и низкого разрешения.
-
Поддержка множества способов сбора данных
Поддержка распознавания изображений, полученных с помощью мобильных телефонов, планшетов, сканеров, цифровых камер и других устройств.

-
Поддержка многосистемных приложений
Поддержка операционных систем Windows (32 и 64 бита) и Linux в различных средах.
Преимущества продукта

Премия за научно-технический прогресс (второе место)
- Технология TH-OCR получила несколько наград, включая вторую премию Государственного научного прогресса и первую премию Министерства образования.

Обслуживание различных министерств
- Используется в таких государственных органах, как Центральный комитет КПК, Центральная комиссия по проверке дисциплины, Налоговое управление, МВД, Генеральная таможня, Министерство иностранных дел и другие министерства.

Высокая точность OCR для отдельных символов
- Распознавание текста на языках меньшинств поддерживает функции проверки слов и комплексной проверки, с высокой точностью распознавания.
Сценарии применения
- Цифровая обработка архивов
- Система безопасности электронных архивов
- Умное оборудование

-
Цифровая обработка архивов
Интеграция WintoneTH-OCR для распознавания документов на языках национальных меньшинств с информационными сервисами, системами умного офиса и системами цифровизации архивов поддерживает управление архивами и цифровизацию. При сканировании бумажных архивов компании система экспортирует данные в форматы двойного PDF, TXT, WORD, XML, XLS, что облегчает редактирование и поиск информации, поддерживая цифровое управление архивами и развитие языков и письменности.

-
Система безопасности электронных архивов
Применение WintoneTH-OCR для распознавания документов на языках национальных меньшинств в системах проверки конфиденциальности, управления безопасностью электронных документов, контроля электронной почты и управления электронными архивами обеспечивает высокую точность распознавания и поддержку защиты данных и управления рисками.

-
Умное оборудование
Внедрение WintoneTH-OCR для распознавания текстов на языках национальных меньшинств в многофункциональные устройства, сканеры или другие интеллектуальные устройства позволяет быстро распознавать и извлекать текст при вводе документов, способствуя цифровому управлению корпоративной информацией.
Примеры клиентов
-

- Считыватель паспортов повышает эффективность регистрации по настоящему имени
-

- Для путешествий устройства считывания паспортов оптимизируют процесс регистрации билетов.
-
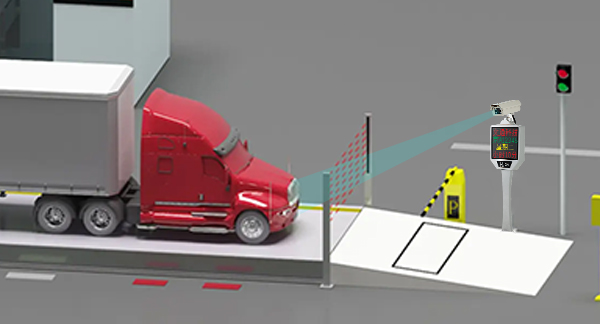
- Камера распознавания номерных знаков помогает автоматической системе интеллектуальной системы управления весами, а технология контролирует перегрузку при взвешивании!
